Это конспект видео по elm. Я делаю такие конспекты, чтобы лучше запоминать материал и легче найти обсуждаю проблему, если мне будет необходимо вернуться к ней в будущем.
Сегодня, законспектируем доклад «Make Data Structures» by Richard Feldman

Ричард работал над редактором для написания книги. В докладе он рассказывает о советах, которые бы он дал себе «прошлому». То есть, какие уроки он вынес приобретя опыт работы в Elm.
Некоторые мысли:
- думать о структуре данных;
- не бить код на модули, как в react (про это было и в докладе Life of file);
- попробовать и «замараться», затем попытаться сделать лучше;
Совет себе прошлому #1: Делать структуру данных
- придумывайте структуру данных, которая отражает UI;
- делайте интерфейс. Делайте «невозможное состояние», невозможным, продумывайте как взаимодействуют части модели;
- отображайте UI (не сразу, а только когда готова структура данных + интерфейс). Обычно, мы сразу начинаем с отображения, а потом думаем о данных. Здесь нужно наоборот.
С 25:45 начинается рассказ про моделирование структуры данных на примере Dreamwriter (редактора, который Ричард делал).
Когда моделируется структура данных, и есть maybe тип, то можно разложить всего его варианты. В докладе, например идет: Loading (Maybe Doc) (Maybe Problem). Стоит подумать, а действительно ли все эти комбинации 2х maybe могут быть?
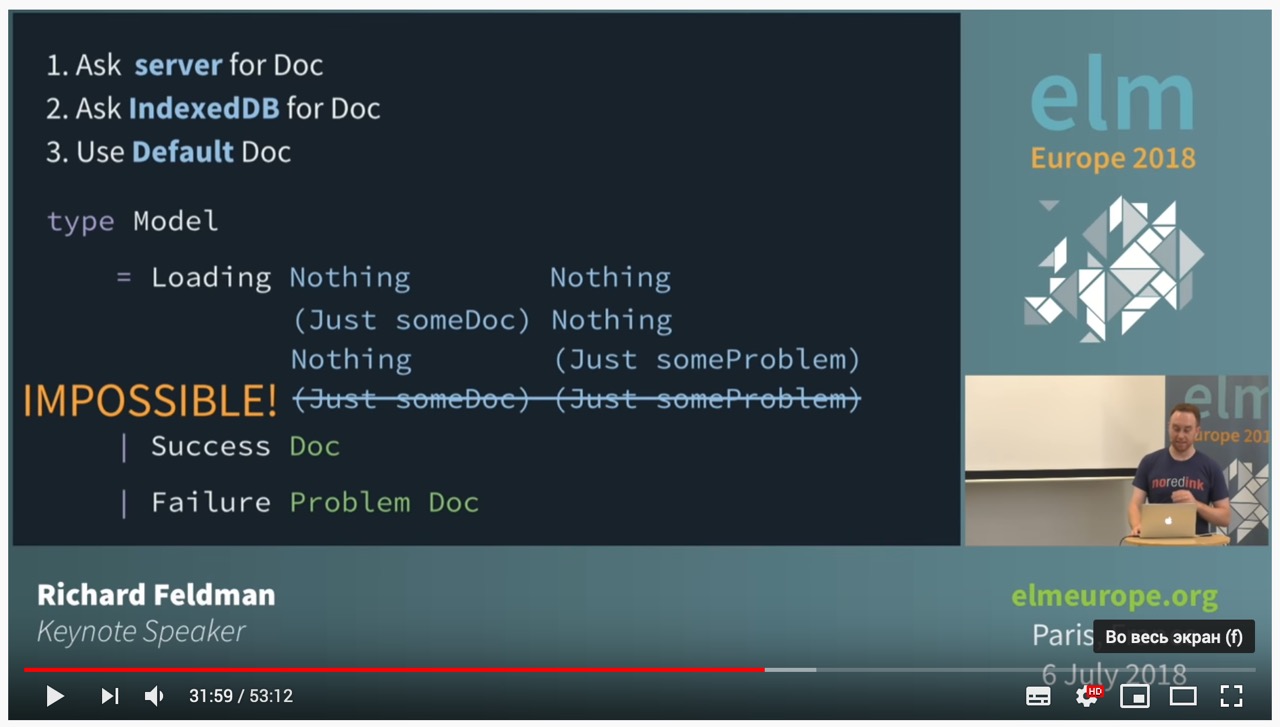
Совет: начинайте с создания типа вручную, и затем, если видите какой-то патерн — используйте готовые типы. На деле это было так: Loading (Maybe Doc, Maybe Problem) (где maybe «готовый тип») превратилось в «созданный вручную»:
Как видим, Loading тип преобразился и отображает только возможные состояния.
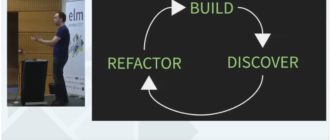
Ричард рекомендует работать по схеме: build -> discover -> refactor. Что подразумевает: что-то сделали, сбилдили. Затем посмотрели как оно работает, вынесли какую-то новую информацию. Если видим, что нужно менять — отрефакторили.
Далее, в примере про view приводится еще один паттерн в Elm — build top level helpers (делайте хэлпер функции высшего порядка). Например:
Здесь, viewLoaded — top level helper. Так же стоит обратить внимание, на то, что у типа Loaded появился один аргумент типа LoadedModel, это record, куда были спрятаны все необходимые свойства. Конкретно для этого доклада, это:
С 39:36 начинается обсуждение моделирования типа Doc (документ, ядро приложения). Причем, сразу же выносится в отдельный модуль.
Началось обсуждение вариантов описания типа для id документа. Если сделать просто type alias DocId = Int, то можем получить не то, что ожидаем:
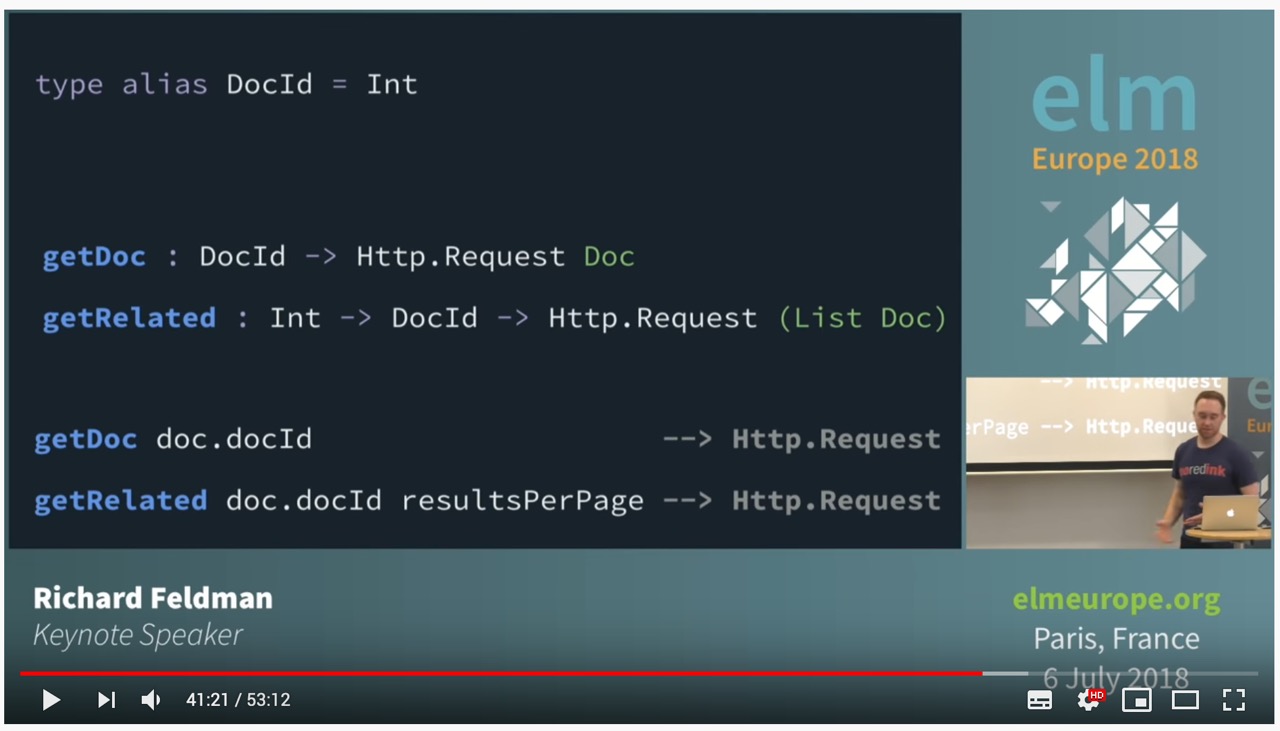
Обратите внимание, на getRelated. Аргументы doc.docId и resultsPerPage перепутаны местами, но так как они оба Int — компилятор не будет ругаться и все «сбилдится». Type alias docId в процессе билда превратится в Int. Рантайм ошибки не будет (не бывает в Elm), однако приложение работает не так, как мы ожидаем.
Решение — использовать кастомный тип:
Перед нами кастомный тип с одним вариантом. Но он сразу же закроет проблему, если аргументы будут переданы не в нужном порядке. Так как DocId будет содержать декодер и энкодер — выделяем в отдельный файл, т.е. модуль.
Так же, Ричард не expose (выставляет наружу) из модуля DocId конструктор типа, в итоге получаем opaque type.
Opaque type (не прозрачный тип) позволяет скрыть внутреннюю реализацию. Вы не сможете пройтись pattern matching’ом по этому типу, что-то поменять внутри… Вы можете работать с DocId только через то, что «экспозится» наружу, в нашем случае это функции encode и decode + сам тип DocId.
В случае с Problem, которая тоже уехала в отдельный модуль, Ричард экспортирует конструктор типа, потому что он хочет использовать «pattern matching» на данном Enum типе.
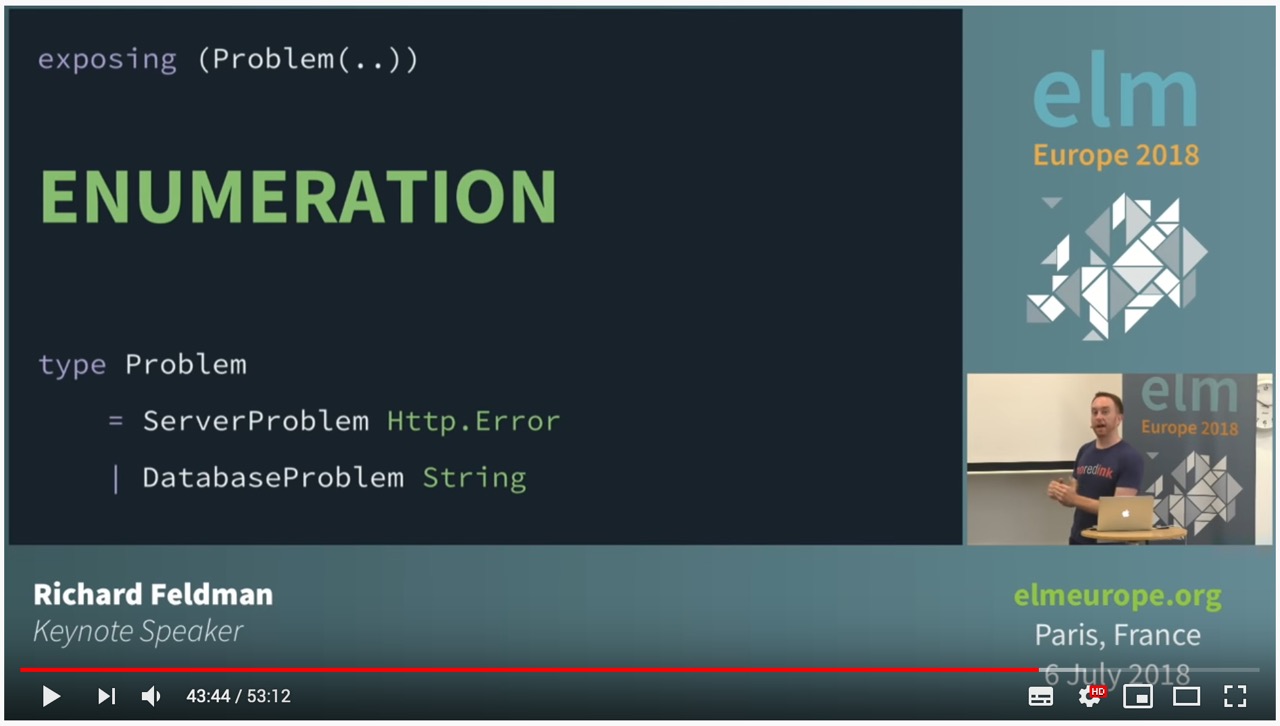
На 46:50 идет речь о том, как можно выставить наружу интерфейс для изменения полей внутри opaque типа в виде record: можно создать функции «мапперы».
В конце показан заключительный слайд «Make Data Structure»:
- начинайте с
type(с описания типа) - используйте opaque тип по умолчанию (в процессе, решайте нужно вам наружу выставлять конструктор или нет, если нет — то пусть остается opaque).